Introduction
When I was thinking about the title and content of this post only word gorilla came to my mind. After that the principle in software engineering that first you write your tests and then you write the code. This is the same principle that I will use in this post. Even though I am not a fan of this approach, as I am more of a let’s test in production kind of guy. Kiddin’ couf ehm.
Building LLM evaluation pipeline
Evaluation metrics
First things first, we need to set some good evaluation metrics that we will follow. These can be:
- Quantitative —> Metrics should compute a score that can be compared. That leaves us an opportunity to set a minimum passing threshold to determine if the model is good or not.
- Reliable —> Everybody hates flaky tests. I had the honor to work with them in the past weeks a lot and there is nothing better then to rerun the tests 10 times just to get the green light. That is why we need at least the tests to be reliable. As LLMs are unpredictable, we need to set a threshold for the metrics that we will use.
- Accurate —> It is not enough for us to have a reliable and quantitative tests, if they are testing something that does not matter to us. We need to align our tests with our expectations as much as possible.
That was more of a general attributes of the evaluation metrics. Now let’s see what metrics we can use.
- Hallucination —> This is a metric that measures how much the model hallucinates. This is a very important metric as it can show us if the model is generating text that is not relevant to the context.
- Correctness —> Determines whether the model is generating correct answers based on groud truth.
- Contextual Relevancy —> Determines whether the retriever in a RAG-based LLM system is able to extract the most relevant information for your LLM as context.
This article about Evaluating Language Models talks about the need for extra evaluation metrics as the basic ones are not sufficient enough to evaluate our custom / specific use-cases. In our case the LLM retrieces the information and we want to know if the information is retrieved from the correct text document or a PDF. This I think can be evaluated pretty easily. Other then that we can measure if enough of the information is retrieved or if the information is relevant to the given context. This is also a good one to have : Whether the summary contains any contradictions or hallucinations from the original text. And the most important as we are implementing a RAG pipeline we will need to evaluate score of the retriever / retrieved context itself.
Scorers and evaluators
Taken from a fact that purely statistical scorers hardly not take any semantics into account and have extremely limited reasoning capabilities, they are not suitable for our use-case. They are also often long and complex to implement. Funny to say, this article wrote “This is because statistical methods performs poorly whenever reasoning is required, making it too inaccurate as a scorer for most LLM evaluation criteria.”, right now we know that apple published a paper that said LLMs do not have reasoning capabilities. Just a fun fact.
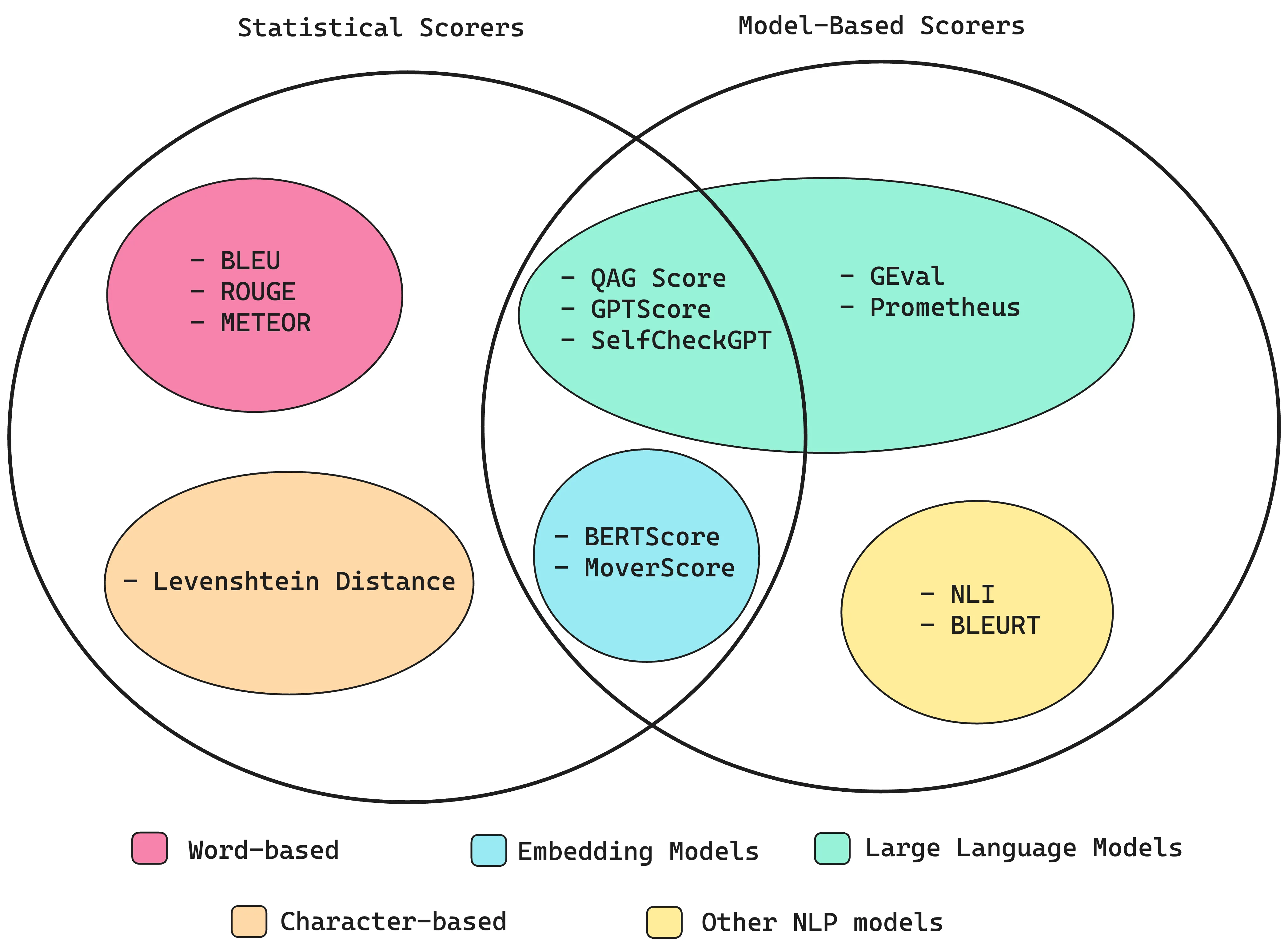
We will be lead by the following:
Scorers that are not LLM-based perform worse than LLM-as-a-judge
Probably the best way to evaluate the LLM, that we will use is G-Eval. It is a framework from a paper published by Microsoft Cognitive Services Research called “NLG Evaluation using GPT-4 with Better Human Alignment”. It uses LLMs to evaluate LLM output.
G-Eval
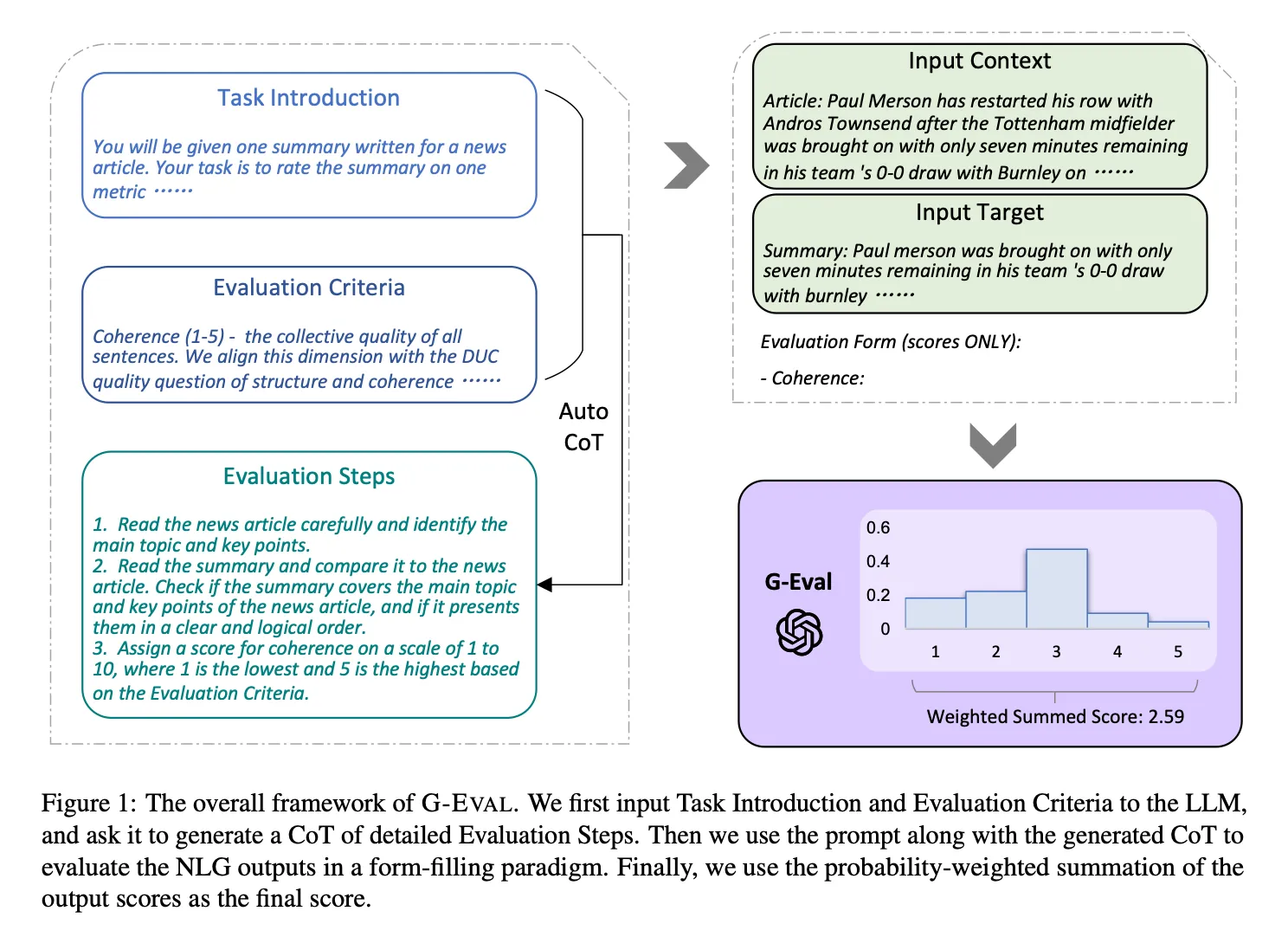
G-Eval follows a “chain of thoughts” (CoTs) approach to guide LLMs through several evaluation steps before assigning a final score based on form-like criteria. For instance, when assessing coherence, G-Eval structures prompts containing the evaluation task and criteria definitions, such as “Coherence—the overall consistency and flow of sentences.” The LLM then generates a score from 1 to 5, representing the quality of output. Optional adjustments, like token probability-based normalization, can provide finer granularity in scoring.
This method aligns well with human judgment, as shown by higher correlations with human evaluation benchmarks. Its flexibility and interpretative ability make G-Eval an accurate and reliable LLM-Eval, enabling evaluations that consider the full semantic depth of LLM outputs. This is crucial, as traditional scorers often miss nuances that LLM-based evaluations can capture, enhancing accuracy in evaluating complex text. I can check out this github repo for python implementation of the G-Eval. There is also another LLM that is more fine-tuned for evaluation called prometheus. As the deep eval uses openAPI models it is not really private in a way that we would like it to be. Prometheus solves this problem in a way but I will have to look into it more. As using the deepeval package would be still an option on one set of data that is not private.

While G-Eval generates the score rubric/evaluation steps via CoTs, the score rubric for Prometheus is provided in the prompt instead. Prometheus also requires reference/example evaluation results. In some way deep eval is more flexible and more easy to use.
CI/CD pipeline
As we have our evaluation metrics set up, we can now implement the CI/CD pipeline. Using a pre-link from previous article, we end up here. It leads us to the deep eval package that we talked about but that is just a prototype. By shifting from static evaluation datasets to dynamic testing with actual inputs and expected outputs, DeepEval enables teams to safeguard against unintended regressions and ensure the reliability of their RAG models as code evolves. The tool’s Pytest integration and customizable metrics, such as RAGAS-based contextual metrics and bias checks, provide fine-grained control over evaluation criteria, making it easy to catch potential issues during development and review phases. Thats why I am adding it into my project and I can also log the evaluations, and when I will switch the building blocks of the pipeline I can see if the new block performs better or worse then the previous one. I think this is more elegant way of doing it then just running the model and then taking the output and then evaluating it. It integrates much better. Anyways, it has pretty nice docs which I will spend more time on. Maybe in the next post, as I will be implementing it. Or I will be reading on something else. We will see.