Introduction
Surprice MF! Yeah, been a long 20 days and I been busy watching Dexter. Thats why the starting reference. It is really good. Anyways, back to business. I had a meeting with my supervisors and the approach I have been cooking in my head looks good to them so we will talk about it and see what we can do. As we now have the PoC, that I described in previous post. Here comes the name of this diary post.
The building blocks
We can take the RAG PoC and like a lego set, or a psycho killer dexter chop it up to blocks that we can glue together and get a working pipeline. From my point of view I would sever the PoC into these blocks:
The data getting
This will be confluence API getting the data as PDFs or even better a text. This is the first block of the pipeline, as we need the data to work with. We will hardly switch this block as it is the core of the pipeline and our hard diamond, that we want to polish and give it as a result to the user. Although I cannot show the private company data when I will be presenting the thesis, so I will build two of these blocks. One from the public data and one from the private data. So I can present it on something. If I match the strucutre / content even better. I used sites of the university subjects that I am taking as of right now for the data that is not accessible to the model. The hindrance is that the content and the structure is quite different from the company data, so I will have to find some better substitute. Quick note, for myself. Maybe I can take something like vanguard PDFs and their reports as it public and new so the model will not have seen it yet.
Data processing
Here it can be split into more blocks, but for simplicity and high level look let’s take it as is. By data processing I mean:
- Cleaning the data
- Splitting the data
- Using packages to better the data
This block is quite important as the data that we get is not in the form that we can use it. We need to clean it, split it into smaller parts and use some packages to better the data. As previously mentioned, better the data, better the results. This implies that we should spend some time on this, also mentioned by my supervisor, as it will be a bigger part of the thesis, but I have already did some analysis on this part, with the PDF documents previously so let’s not get stuck on this block too much and move on.
The embeddings
We talked about this quite a lot on both meetings that I got, as the whole pipeline can be seen as data & LLM model. So connecting this block with the data processing and data getting could make up a part that is the core of the thesis and plugging it only to the model. The main thought behind it was that we do not want to embed the data everytime, same with parsing and cleaning it, if the data doesnt change of course. So we will have to make a system that will check if the data has changed and if it has, then we will reprocess it. But if not we can skip these three parts, making it faster and more efficient. This was more of a pieces together thought, but there is of course more to this part then this. There are multiple embedding techniques that we can use and play with. We will bechmark them and see which gives as the best results.
The model
Not much here to be said as we will test only two models, if the future doesnt give us a better ones. The models that we will test are:
- Llama 3 8B
- Misntral 7B
I hardly doubt that we will use anything other then these two, as these are the best small models that we can use as of right now. Our specs are quite limited, as we are using personal laptops, maaaybe there is a chance that I can get my hands on a better computer to run the really good 80B model from Meta, but that would defeat the purpose of the thesis. As we are trying to make it as available as possible to the employees of the company. So we will stick with the small models. Unless I would like to test it and play with the big model.
Prompt templates
This can play a huge part in the results that we get. How we ask the model the questions. A lot of room for improvement here, and experimenting. We will have to see what works the best and what doesn’t. Maybe we can create a system that will test the templates, or we can do it ourselves. Buut run the same question on different templates and see what the model gives us. Storing here a link to the template that I got to check out. And I will get back to when I will be working on this part.
The pipeline
Combining all these building blocks together we get a pipeline, but as we can see in the picture below:
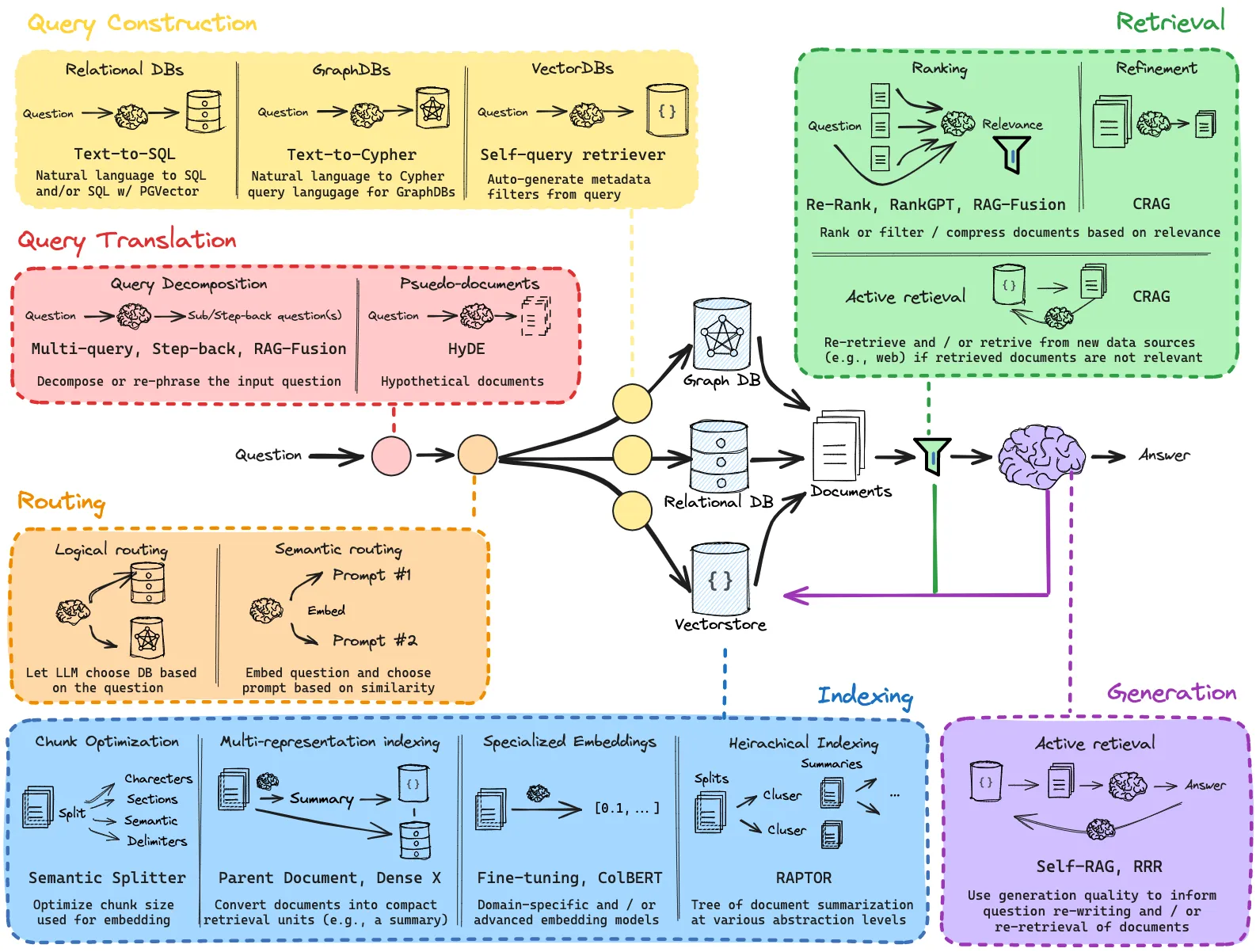
Also there is this graph that I have shown in the last post.
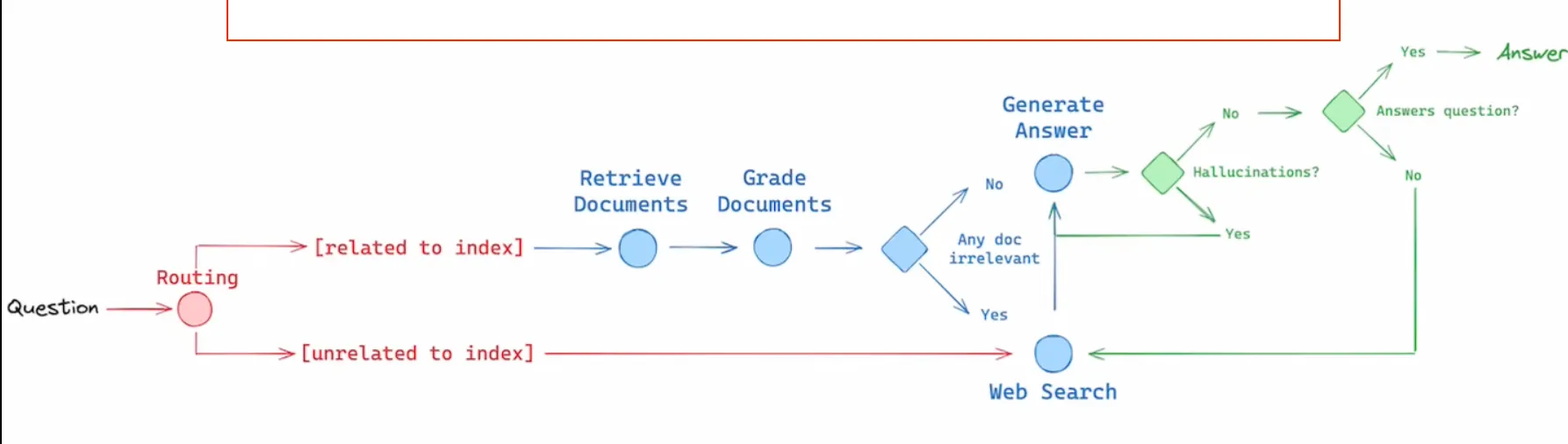
I will have to draw some combination of these as I could not find one that was my favourite. Either way, as we can see from these piplines it is not that simple and we can implement a lot of methods on top of these small building blocks. Also I got a suggestion from my supervisor to implement a technique that the newest openAI model uses. Basically make the LLM “think longer” that could mean run the model multiple times on the same data and see if the results get better. Or even use the results to generate one ultimate answer. I think I will find some paper published on this. The conclusion is that we have a lot of work to do and a lot of experimenting to do.
Testing the pipeline
This was the overview, how I look at the pipeline. The plan for now is to read stuff on the internet for a particular building block, implemnt the block and try to test it out. The testing / benchmarking is was tricky to me but on the meeting I had the supervisor said that I can define the parameters. As the LLM returns words that I myself can evaluate if I like the response or not or it is relevant to the question. So I will have to define some parameters that I will use to evaluate the results. There are also parameters as the time that the model takes to respond, that I will take into account for sure in a certain way. As it does not really matter to me if it is 10 or 15 seconds, but if it is 10 or 1 minute, then we have a problem. And maybe the resources that it takes to run the model. Thats about it for now. I will take a look into how the LLM are benchmarked and see if some of the techniques or parameters are useful to me. Virtual blog note to take a look at this.
Conclusion
That’s about it. I categorized the parts, now I will have to dive into them and see what I can do. But first seasson 2 of 🔪Dexter🔪 is waiting for me. 🍿