Introduction
After some time spent on knowledge embedding techniques, I decided to take a step back and focus on the data I will be working with. As I do not have access to company data yet, I decided to create my test data from mathematical books and PDFs. I will use this data to test different parsing modules and see which one works best for my case. I will also explore the limitations and performance of each module. So, let’s dive into the world of parsing! Finally some python code! Well just a tiny bit, from importing the modules and reading the PDFs. As I progress I am planning to create a pipeline that will scrape the PDFs and Docs from conffluence and parse them. But that is a story for another time.
Resources available
I found several Python modules that can be used for parsing PDFs. The most popular ones are PyMuPDF, pdfplumber, and PyPDF2. I will start by testing these modules on a sample PDF file and compare their performance and results. I will also explore other modules if needed. I will also have to see how they work with mathematical equations and if they can parse them correctly. As I will be working with them a lot. Mostly mathematical equations, simple ordered tables I hope and text of course. From what we know now the data we use is KING. So it has to be parsed with as much precision as possible. And also the format needs to be good. Thats why the saying goes
Garbage in, garbage out
or just basically
The better data we provide the better results we get
Thats why we will incorporate data cleaning into the pipeline. I do not know how yet, as I feel like it will have to be partly manual. But work will tell. Given my research so far, about modules available these are the most popular ones:
- PyMuPDF
- PdfPlumber
- PyPDF3
- PDFMiner
- Camelot
There are more, but these are the most popular just for PDF parsing. I also found some other modules for getting data into LLMs, I will check out RagFlow but I am more interested more in their DeepDoc module. It uses OCR for getting information from docs, PDFs etc. I will have to see how it is implemented and if it is worth using. They are open-source and have discord which is always nice. Other then that LlamaIndex is a valid choice. Although it is not open-source, which raises some conserns from the privacy point of view. I used it previously and it was better then just some regular PDF parsing module. But privacy is not a thing I can take lightly. I have to say that I am really impressed with LLMWhisperer, the results they are presenting from unstructured data are insane. Unlucky for me, it is not open-source, they use API that probably takes the information and they are paid. Other then that their github was impressive. So I wanted to mention them. The plan is to use open-source modules, so I will check the DeepDoc from the RagFlow, and unstructured. Althouth the unstructured is a module more for cleaning the data, then parsing it. But the step for cleaning is important as we want quality data.
RAG Engineer’s Guide
I have came across this interesting reddit post that talks about RAG with focus on parsing documents. Where they say:
parsing is the bedrock of any RAG application
Talking about that if we input thousands of PDFs into our LLM, they will eventually cause a hallucinations. So we have to create a way of breaking complex documents apart, identifying the text blocks, the tables, the charts and so on, then extracting the information from those positions and converting it into something language models will understand. Resulting in a simple JSON or plain text. After that they show us some photos of different parsing modules react to the same PDF of some medical document. I will share them here, as they are interesting.

Image: PyPDF results showing minimal information extracted from the table in the medical document.

Image: Unstructured results showing rich information extracted from the table in the medical document.
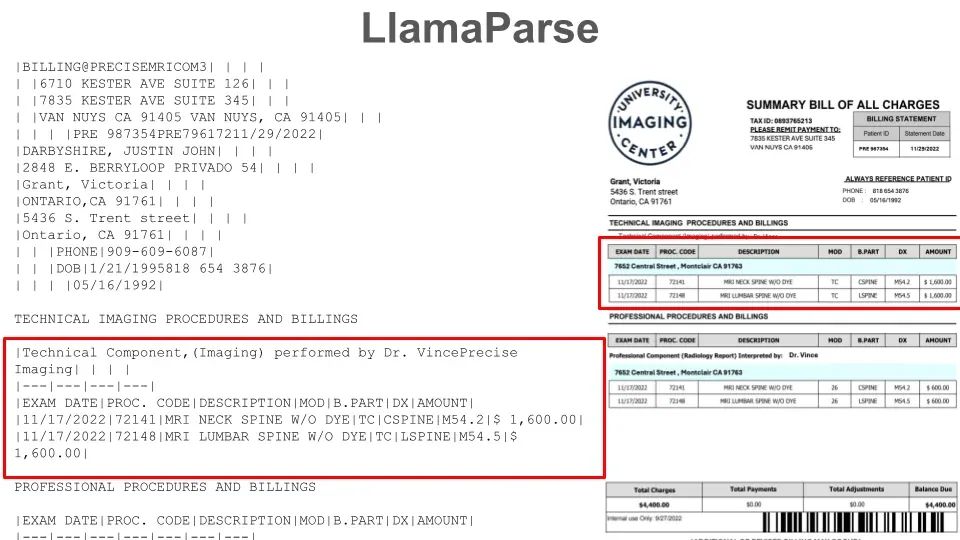
Image: LlamaParse results showing a markdown table of information extracted from the table in the medical document.
They are later quoting and pointing out, how the parsing can influnce RAG and massivly improve the results / performance. Saying that maybe we should be focusing more on the parsing side, then on the optimazation strategies. That there are bigger gains to be made in the parsing. I will have to see how the parsing will work with my data, but I am keeping my hopes up. Later listing some usual Pitfalls of parsing, like:
- Tables - They are a nightmare to parse, especially if they are not well structured. It can be treated as unsturctured data, if the parser fails to recognize the table.
- Images - They are not text, so they are not parsed. But they can contain valuable information. OCR can be used to extract the information from the images.
- Loss of Formatting - If the parser does not understands the formatting, it can lose the information. The header can scramble up with the text, or the text can be lost.
Custom Parsing
As I will not be able to use the “not open-source” parsers, there is a thought of creating a custom parsing strategy. This would mean that there is some pattern, structure that the data I will be parsing has. If there is, we can meantion here some of the common approaches:
- ML Augmentation - Using ML to augment the parsing. This can be used to improve the results of the parser. It can be used to recognize the tables, images, text and so on.
- Regex - Using regex to extract the information. This would mean that there is specific pattern that can be used to extract the information.
- Combining Modules - Using multiple modules to parse the data. Taking the best results from each module and combining them into one.
Also implementing some custom cleaning strategies, as we may expect some complications with the data. This would mean we can focus on the pain points / halucinations of the parsers and try to fix them. This would mean that we would have to have some manual work in the pipeline. Or deleting some data that is likely needed for the LLM. But we will see how it goes.
As we will work with multiple data formats, mostly PDF and Docx, we will have to create some Data Format Consistency. Because the more structure our data has, the better the results will be. Just something to keep in mind, when developing the pipeline. We could combine it with Error Handling. As we will have to expect some errors while parsing, unexpected data or data formats.
Something to consider before jumping in
As everybody knows measure twice, cut once, visualy inspect the data you are about to be parsing and feeding the pipeline. Open the PDFs, Docs and see how they look. This will give you a better understanding of what you are working with. With this understanding, create little experiments to see how the parsers react to the data. Take some modules and run the date trough them. No need for complex code, and use brain and eyes to see which way to go. This will save you time in the long run.
This will narrow down our choices, but maybe some model will not work with the whole pipeline. That would mean that we need to test from start to finish. And comparing the strategies. Considering time it takes to parse the data, the quality of the data and the results.
Remember, in the world of RAG, your system is only as good as the data you feed it. And that all starts with parsing.
What’s next
Today, we explored only PDF parsing modules mostly. Of course some of them support multiple formats. I tried some of the parsers on my own and I will share my results probably next time. :smile: While writing this “dev driary / blog” I learned that in the confluence I can choose to export into PDF or Docx and as everybody knows its lot easier to parse text then images. Soo upon next time, I will expolore confluence API to grab all the files, most preferably in the text format. And then I will try to parse them. That means other parsing modules, and maybe some custom parsing. There are formulas / equations written inside of Docx and I do not know how the parsers will react to them. So I will have to see. Upon that maybe the first structure of a pipeline will be created. But that is a story for another time. Upon next time my dear reader!